How to Do a Group by and AVG in PySpark?
- How to Do a Group by and AVG in PySpark?
- PySpark Group By enables group by and avg operations
- SQL syntax
- Aggregation expressions
- Result values of grouping expressions
User Review
( votes)This article covers how to do a group by and AVG operations in PySpark. It includes SQL syntax, Aggregation expressions, and Result values of grouping expressions. You can use the grouping expressions to sort your data and analyze trends in your data. You can also use PySpark to do this with Tableau. Once you have these data structures, you can perform group by and avg operations on them.
PySpark Group By enables group by and avg operations
You can perform aggregate and group by operations in a data frame using the avg and group by functions. To create a group by dataframe, you must have at least one column. The first step in creating a group by dataframe is to create an RDD by using sc.parallelize. You can then use the SUM function to determine the average value of a column.
You can also use SQL commands to improve the efficiency of the Data Pipeline. Using SQL functions, you can extract complex data from different data sources. Databricks SQL commands can help you extract data from a variety of sources and then store it in a single location. Databricks SQL commands make it easy to move data from one data source to another. You can even automate the process with Hevo.
You can also use avg or group by in a databricks query. The avg function enables you to perform advanced aggregations. Using avg or group by databricks’ runtime, you can apply multiple avg expressions in a single query. The avg function allows you to do multiple calculations at the same time, and you can combine grouping expressions for more complicated calculations.
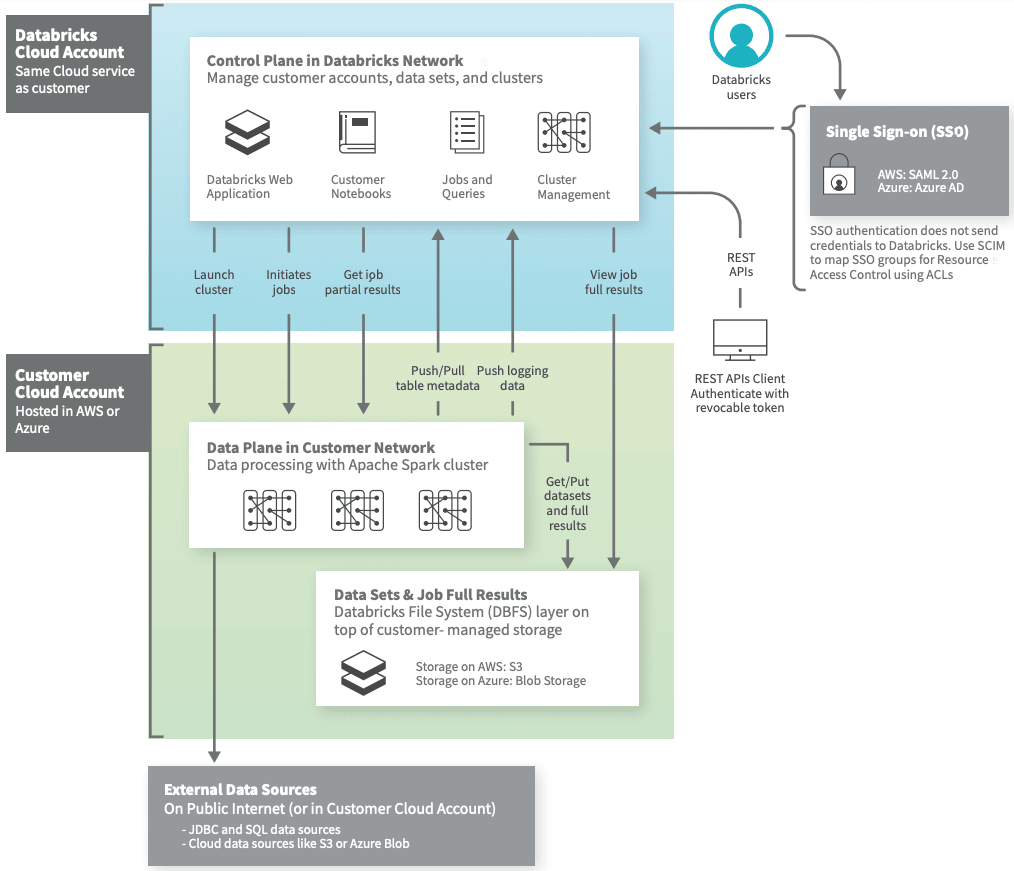
Databricks is a Cloud-based data platform that is powered by Apache Spark. The main focus of the platform is on Big Data Analytics and Collaboration. It features a Machine Learning Runtime, managed ML Flow, collaborative notebooks, and Spark SQL libraries. The main features of the Databricks platform include machine learning, predictive analytics, and machine learning.
SQL syntax

You might be wondering how to write SQL statements to group by and avg your data in Databricks. The answer is pretty simple, but it can be difficult for some people. For example, if you need to calculate a total revenue by customer, you could use the CREATE TABLE LIKE command. This command creates a table based on a definition.
The GROUP BY clause uses grouping expressions to group rows, then compute aggregations for the resulting set. Databricks SQL supports advanced aggregations, which means that you can use more than one aggregate for the same input record set. You can also use nested and mixed aggregations in Databricks SQL. This type of aggregation is covered in the Mixed/Nested Grouping Analytics section.
GROUP BY is a common query, but you may be wondering how to use it in Databricks. The GROUP BY command groups results by a specified criterion. The GROUP BY command is often used with an aggregate function such as COUNT, MAX, MIN, or SUM. This SQL syntax can be tricky to understand, but with a little practice, you’ll get the hang of it.
Using windowing functions in Databricks is an excellent way to perform various operations on a set of data. It is a great alternative to using loops and can handle a variety of use cases. Be aware that you may be shuffling data if you use this SQL syntax, but the advantages of using it are great. The Databricks notebook will let you play around without the need for external storage.
Aggregation expressions
For computing the average or median of a set of values, you can use the mean() function. It returns the mean of a set of values. You can specify the columns to use as inputs. If you don’t specify columns, you will get an unknown number of unique values instead. This function is similar to pandas’ aggregate function. You can use it in combination with the groupBy function.
GROUPBY is a multiple column function. It groups data based on a key value. To do this, data is shuffled across the network and brought to the same place. Then, you can apply a condition. If the condition is true, the data will be grouped. This function is most often used in conjunction with the aggregate functions. The groupBy function is used to get the mean of a set.
In addition to a table’s definition, you can also use the CREATE TABLE LIKE command to perform a grouping operation. This command creates a table based on the definition. This allows you to see live data flow and make alterations without coding. For a free 14-day trial, sign up for Hevo. Once you’ve installed and customized the database, you’ll be able to make use of its SQL functions to enhance your data warehouse and Data Pipeline.
Result values of grouping expressions
You can create GROUP BY… GROUPING SETS with Databricks Runtime. These aggregations are computed based on a set of rows. Databricks Runtime supports advanced aggregations that can mix and nest together. You can also create grouping expressions with a FILTER clause, which will only pass the matching rows to the aggregate function.
To use grouping expressions, you can select a table, a column with a name, and a column that represents the groups. Then, enter the grouping expressions. The values of the groups are returned in a new column. Note that the grouping expressions must be a single function or constant. For example, you can select the columns for a column by its name, and then use the grouping expression to retrieve the grouped values.
The results of a grouping expression in Databricks are created using SQL commands that are built on top of the data warehouse. When you have complex data sources, you can use SQL commands to extract the data. Using these commands, you can easily extract complex data from various data sources and transform it into a single view. This allows you to create complex reports, or to make ad-hoc analysis.
In addition to the grouping expression, you can use the cube or rollup methods to summarize data. You can also use a number of aggregate functions in Databricks, including sum, count, and count. These functions perform the same operations as group(), but they do not require an order in which to pass the arguments. The cube() function takes a list of columns and applies aggregation expressions. It is a bit less common than group(), but is very useful when performing analyses in large datasets.
We look forward to your comments and stars under the topic. We thank you 🙂